1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| #include <stdlib.h>
#include <stdio.h>
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include <opencv2/opencv.hpp>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#ifdef _DEBUG
#pragma comment(lib, "opencv_core247d.lib")
#pragma comment(lib, "opencv_imgproc247d.lib")
#pragma comment(lib, "opencv_highgui247d.lib")
#else
#pragma comment(lib, "opencv_core247.lib")
#pragma comment(lib, "opencv_imgproc247.lib")
#pragma comment(lib, "opencv_highgui247.lib")
#endif
__global__ void swap_rb_kernel(const uchar3* src, uchar3* dst, int width, int height)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
if(x < width y < height)
{
int offset = x + y * width;
uchar3 v = src[offset];
dst[offset].x = v.z;
dst[offset].y = v.y;
dst[offset].z = v.x;
}
}
void swap_rb_caller(const uchar3* src, uchar3* dst, int width, int height)
{
dim3 threads(16, 16);
dim3 grids((width + threads.x - 1) / threads.x, (height + threads.y - 1) / threads.y);
swap_rb_kernel<<<grids, threads>>>(src, dst, width, height);
cudaThreadSynchronize();
}
int main()
{
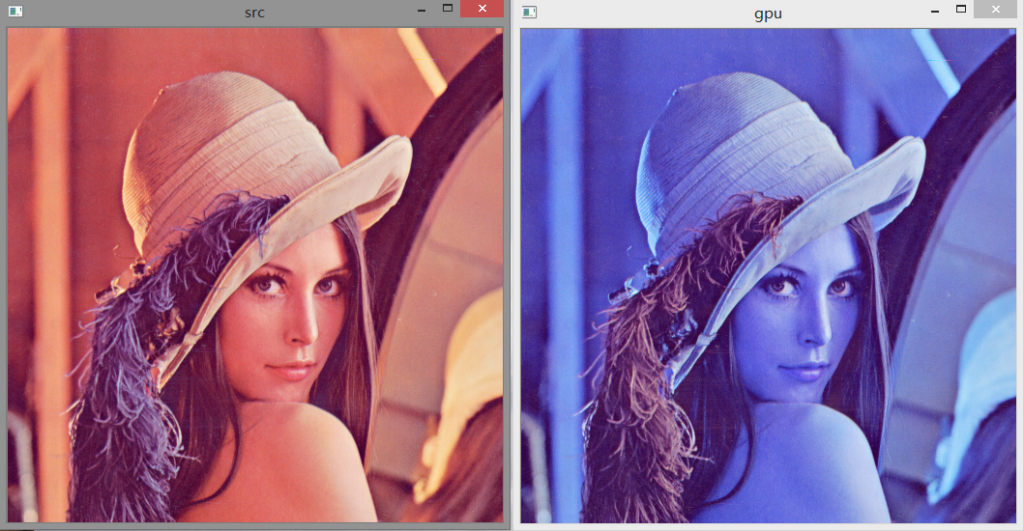
cv::Mat image = cv::imread("lena_1.jpg");
cv::imshow("src", image);
size_t memSize = image.step * image.rows;
uchar3* d_src = NULL;
uchar3* d_dst = NULL;
cudaMalloc((void**)d_src, memSize);
cudaMalloc((void**)d_dst, memSize);
cudaMemcpy(d_src, image.data, memSize, cudaMemcpyHostToDevice);
swap_rb_caller(d_src, d_dst, image.cols, image.rows);
cudaMemcpy(image.data, d_dst, memSize, cudaMemcpyDeviceToHost);
cv::imshow("gpu", image);
cv::waitKey(0);
cudaFree(d_src);
cudaFree(d_dst);
return 0;
}
|