需要注意的是,本文涉及的内容过多过杂,基本涉及到游戏渲染和图形管线的方方面面。内容是根据多方面的资料整理而成,比如本人的Unity和Unreal引擎相关的理解和认知,以及引擎相关官方文档等,以及DirectX和OpenGL相关官方文档等,以及网络上各种相关文章和资料等。可能有一些纰漏或者不足之处,或者有些阶段的资料来源较为单一,本人主要目的是从概念理解上对应整个游戏引擎的渲染管线,不一定和真实的游戏完全一一对应,比如应用程序阶段的知识对应到游戏引擎应该会有一些区别和取舍,几何阶段和光栅化阶段主要参考的是OpenGL和DirectX,Vulkan和Metal相关资料参考较少,可能不同的图形API会有一些出入。由于涉及内容过多,难免理解不到位,有发现比较明显错误的,请指出以尽早修正,避免造成误解。
一、渲染管线的思维导图
这是本文内容的思维导图,通过该图可以从整体上把握全文的内容,对渲染管线有整理的理解。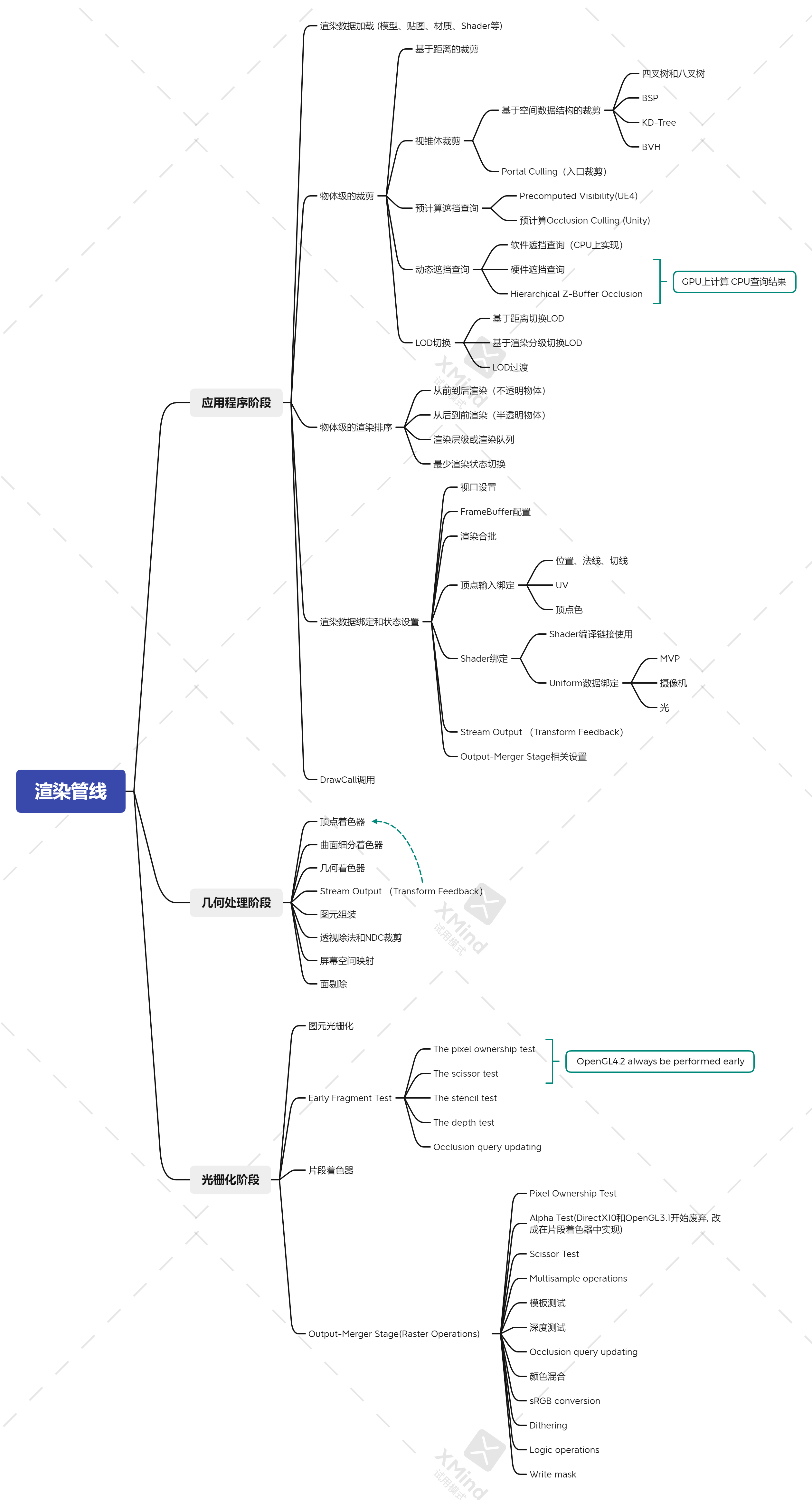
二、应用程序阶段
2.1 渲染数据加载
这个阶段指的是将渲染所需要的相关数据,比如模型、贴图、材质、Shader等加载到内存中,通常只发生一次,不需要每帧重复加载。比如,Unity游戏需要在运行时,将需要的场景或者人物从AssetBundle中加载出来,然后引擎才能显示加载的场景或者人物。
2.2 物体级别的裁剪
以下描述的裁剪算法是按照粒度从粗到细的裁剪,相应复杂度和代价也是在递增。最简单的是基于距离的裁剪;然后是利用空间数据结构实现的视锥体裁剪;动态的入口裁剪是一种特殊情况,可以算在视口裁剪内也可以用于预计算;然后预计算数据的裁剪;接下来才是动态的遮挡剔除。
2.2.1 基于距离的裁剪
思路是超过一定的视距即不渲染该物体,Unreal引擎支持这个特性,参考Cull Distance Volumes。对于Unity,可以使用CullingGroup实现类似的功能。即使引擎没有提供类似的支持,在游戏逻辑层面,先可以每帧或者隔帧判断物体跟摄像机的距离,来动态显示隐藏物体。
2.2.2 视锥体裁剪
用物体跟摄像机视锥体做相交测试,将完全没有相交的物体过滤掉。为了加快速度,使用的是物体的包围盒或者包围球跟视锥体做相交测试。游戏引擎内一般都会有空间数据结构来组织物体,比如BVH,那么可以直接使用BVH来搜索加速这个计算。具体过程是用视锥体和空间数据结构去做相交测试,如果当前节点没有相交,那么不需要继续,如果有相交则继续遍历子节点直到叶子节点或者没有相交,叶子节点中存储的物体即是需要渲染的物体。
基于空间数据结构的裁剪
四叉树和八叉树
四叉树对应的是二维空间,下面以八叉树为例来说明。八叉树是将三维空间平均划分为八个部分作为八个子节点,重复划分到一定的粒度为止,比如叶子节点内最多存储多少个物体,物体存储在叶子节点内。
优点:概念和实现简单。
缺点:无限空间不好划分;物体可能跨越分割面;物体分布不均匀会造成层次过深,搜索效率不高。
适用场景:四叉树适用于基于高度场的地形管理;八叉树室适用于室外分布均匀的三维场景(有高度)。
BSP
针对八叉树这种不均匀划分,如果将物体均匀划分成两部分,那么就是Binary Space Partition Tree,可以避免树的层次过深。注意,BSP的每个节点存储的是划分平面,而不是物体,划分平面将场景分为前后2个部分,分别对应左右子树;由于需要BSP树针对的多边形,因此可以针对物体的AABB包围盒做划分。
优点:物体分布均匀,不会出现树层次过深;支持任意空间。
缺点:实现复杂,构造时间长,不适合动态场景。
适用场景:紧凑并且分布均匀的室内场景;静态场景;自带物体排序,方便实现画家算法。
KD-Tree
BSP全称是K-Dimensional Tree。这是一种特殊的BSP,在BSP上进一步将划分面限制跟坐标轴垂直,但是保持从物体分布的中间划分,以尽可能得到一个物体分布均匀的树。KD-Tree不仅仅可以用来做空间划分,在其它领域经常用来组织K维度的数据来做搜索,比如K维数据查询、近邻查询。
优点:物体分布均匀,不会出现树层次过深;数据可以组织为数组形式的完全二叉树,缓存友好等。
缺点:如何确定最优或者较优的划分面?
适用场景:紧凑并且分布均匀的室内场景;辅助其它数据结构进行邻域查询。
BVH
全名是Bounding Volume Hierarchy,中文翻译层次包围盒。BSP和KD-Tree的节点代表的都是分割面,但是面有可能穿过物体。层次包围盒的思想是每个节点代表一个空间,空间计算其包含物体的最小包围盒,划分空间后重新计算子空间的包围盒。与BSP最大区别是节点代表的不再是分割平面而是包含最小包围盒的子空间。因此,这些子空间可能出现一定的重叠,但是不会出现物体出现在不同的划分里面。
优点:节点存储的是物体,方便碰撞检测等查询;构建快,动态更新方便。
缺点:如何确定最优的包围盒?
适用场景:视锥剔除;物体碰撞检测;射线检测;光线跟踪。
空间数据结构的其它应用
除了视锥体裁剪外,空间数据结构还有很多其它应用,比如
1、Ray Casting (射线检测)
2、碰撞检测
3、邻近查询 (比如查询玩家周围敌人)
4、光线追踪
Portal Culling(入口裁剪)
适用于将场景划分为格子,格子之间可能存在入口的情形,如下图所示,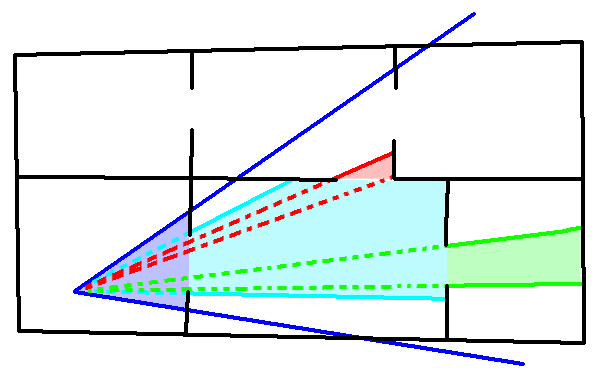
从入口只能看到部分被墙壁遮挡住的物体,因此可以借助这个特性加速视锥体和格子的相交裁剪。Unity中的Occlusion Portal即是这个特性。如果预计算出Protal Culling的结果,那么可以在运行时加快物体裁剪。
2.2.3 预计算遮挡剔除
这是一种空间换时间的算法,会增大内存占用,降低Cpu的裁剪消耗。所以是否需要预计算遮挡数据,还需要具体讨论。一般如果内存消耗不大,但是Cpu占用较高的话,可以尝试开启预计算遮挡数据。
Precomputed Visibility (UE4)
参考虚幻引擎的Precomputed Visibility。思想是将场景划分为格子,计算每个格子内可以看到的可见物体集合相关的数据,用于运行时动态查询。
预计算Occlusion Culling (Unity)
参考Unity的Occlusion culling。类似于UE4的Precomputed Visibility,不过Unity的Occlusion Culling也支持动态物体,但是动态物体只能occludee(被遮挡物体)。Unity的预计算Occlusion Culling应该是入口剔除的一种预计算实现。
2.2.4 动态遮挡查询
这里讲的是在CPU上或者GPU上实现的遮挡查询。图形API已经提供了遮挡查询相关的接口,比如OpenGL的Query Object或者DirectX的Predication Queries。但是不是所有的硬件都能够支持,因此可以在软件层面即在CPU上做软渲染实现遮挡查询。Hierarchical Z-Buffer Occlusion则是在普通的硬件遮挡查询上的进一步优化,使用了层次Z-Buffer来进一步加快速度。
软件遮挡查询
软光栅化模仿硬件遮挡查询,因此不受设备类型限制,只是需要额外消耗CPU。
硬件遮挡查询
使用图形接口本身提供的遮挡查询接口。基本思想是用物体的包围盒去渲染Z-Buffer,统计通过深度测试的像素数目,如果有通过说明当前物体没有被完全挡住,保存结果用于下一帧查询。因此,硬件遮挡查询会存在两个问题:额外的渲染消耗和延迟一帧。
Hierarchical Z-Buffer Occlusion
类似硬件遮挡查询,不过使用Hierarchical Z-Buffer来加快查询速度。具体实现比较复杂,请参考相关文章。
2.2.5 LOD切换
LOD指的是Level Of Details。如果物体通过了以上的裁剪,那么说明会提交给渲染线程进行处理。LOD切换指的是这些物体的细节层次切换,比如一些不重要的或者看不清楚的物体选择更简单的模型。
基于距离的LOD切换
最常见的方式是根据摄像机距离来进行LOD切换,越远的物体选择更简略的LOD,Unity和UE4默认是这种方式。
基于渲染分级切换LOD
但是我们也可以主动切换LOD,比如检测到当前硬件较差,需要切换到更低的画质,那么可以根据游戏设置的渲染品质分级来切换低的LOD。
LOD过渡
LOD的一个常见问题是LOD的过渡问题,可能在切换LOD时候会察觉到明显的过渡。常见的方式是在切换时候混合2个LOD,比如透明度逐渐从1变化到0或者从0变化到1,避免出现明显的过渡。
2.3 物体级别的渲染排序
为了减少OverDraw或者实现半透明效果,所有通过裁剪的物体会按照一定的次序进行渲染。下面列举几个常见的渲染次序。游戏引擎实际的渲染过程还会跟引擎渲染管线的Pass定义顺序相关,比如不透明和透明物体在不同的Pass内渲染的,而且是先在一个Pass内渲染透明物体,再在另外一个Pass渲染透明物体。
从前到后渲染(不透明物体)
从前到后渲染可以利用Early Z-Test过滤掉不必要的片元处理。因此,如果先渲染近处的物体,那么后面渲染的远处物体就不会通过Early Z-Test,就不会进入片段处理阶段。不过,不是所有的硬件都需要按照从前到后的物体顺序进行渲染,这毕竟需要额外的CPU消耗来排序物体,部分支持HSV(hidden surface removal)特性的GPU,比如PowerVR是不需要做这个排序的。Unity提高了静态变量SystemInfo.hasHiddenSurfaceRemovalOnGPU来查询GPU是否支持HSV,
Urp渲染管线会根据这个来判断是否需要跳过从前到后排序物体。
从后到前渲染(半透明物体)
由于半透明物体的渲染算法要求必须从后到前渲染物体,同时关闭深度测试 ,前面的物体与后面的物体进行颜色混合。那么这个排序过程是无法省掉的,类似从前到后渲染的排序,可以采样BSP来排序物体。
渲染层级或渲染队列
Unity同时定义了这2种排序,不过SortingLayer的优先级更高,这个是定义在物体的Renderer组件上。RenderQueue是定义在Shader和材质上,优先级在渲染层级之后。理论上,就是对所有物体进行优先级排序。
最少渲染状态切换
还有一种方式是尽可能在渲染物体的时候避免渲染状态切换,这样能够尽可能减少CPU消耗。那么可以在CPU计算出来一个最优的渲染顺序来尽可能减少渲染状态切换。
2.4 渲染数据绑定和状态设置
这一个阶段讲的是在CPU上设置渲染相关数据和状态,以及为了减少渲染状态切换的渲染合批的思想。
视口设置
设置窗口的渲染区域,比如OpenGL的glViewport。通过这个设置,我们可以在一个窗口上渲染多个不同的视口,比如游戏的分屏。
FrameBuffer设置
一般游戏引擎不会直接将物体渲染到默认的渲染缓冲上,单独的RenderTarget方便进行后处理,在后处理之后再Blit到默认缓冲上。一个FrameBuffer可以包含颜色、深度、模板三个附件,也可以将深度和模板组织成一个32位的RT。
渲染合批
渲染合批指的是为了减少渲染状态切换的一种优化手段,Unity URP渲染管线的SRP技术可以大幅度优化渲染批次。这是一个在Shader变体层次的合批,与之前的材质层次的合批相比有很大的优化。
顶点输入绑定
对于OpenGL来说就是创建和绑定VAO(Vertex Array Object)。一个VAO中可以包含VBO(Vertex Buffer Object)、IBO(Index Buffer Object)。然后用glVertexAttribPointer和glEnableVertexAttribArray指定数据到Shader的输入变量。
顶点属性通常包括,位置、法线、切线、UV、顶点颜色等。
Shader绑定
渲染数据绑定好之后,需要指定当前使用的Shader,这包括Shader的编译链接和使用等(假设Shader代码已经加载进来)。
Shader编译链接使用
类似于CPU上运行的程序,Shader也需要编译链接以及开始使用的过程,不过这个过程基本上是固定。
可以参考learnopengl的着色器一节。
Uniform变量绑定
Shader中通常会有很多全局变量,比如MVP、摄像机位置、光的信息等。这些都需要在CPU上传入Shader中。
Output-Merger Stage相关设置
在渲染管线的最后(片元着色器之后),有一个Output-Merger阶段,也叫做Raster Operations。这是一个不可编程阶段,但是有很多选择可以设置。比如剪切测试、模板测试、深度测试、颜色混合因子和函数、sRGB转换等。这些都需要在应用程序阶段进行设置。
2.5 DrawCall调用
终于到了应用程序的最后一步,即DrawCall的调用了。OpenGL对应的接口是glDrawArrays或者glDrawElements。
三、几何处理阶段
这是第二个大的阶段,当前阶段已经进行GPU中了。该阶段的起点和主要过程是顶点着色器。除了着色器之外,其余阶段都是硬件自动进行的,除了可选阶段之外,其余的都是固定的,应用程序无法根据配置来进行更改。
3.1 顶点着色器
顶点着色器的处理对象是应用程序阶段绑定的每个顶点,顶点着色器会获得顶点属性以及相应的Uniform变量。顶点着色器的输出是一个NDC Clip Space的顶点位置。NDC(Normalized device coordinates)是规范化设备坐标系的位置,OpenGL的范围[-1,1],DirectX的范围是[0,1]。之所以说是Clip Space,因为该阶段得到的顶点数据是一个齐次坐标,还需要进行透视除法,即x、y、z除以w分量才能得到NDC坐标系下的位置。
3.2 曲面细分着色器
曲面细分着色器是一个可选阶段,用于将一个简单模型细分成复杂的模型。其实该阶段是2个着色器和一个固定阶段的组合。在DirectX中叫做Hull Shader stage、Tessellator stage、Domain Shader stage;在OpenGL的Tessellation中叫做Tessellation Control Shader、Tessellation Primitive eneration、Tessellation Evaluation Shader。具体的介绍和使用方式请参考相关资料。
3.3 几何着色器
几何着色器也是一个可选阶段。几何着色器的输入是图元的顶点集合(比如三角形图元有三个顶点,点图元只有一个顶点),输出是一个新的图元,新的图元也要包含一个顶点集合。简单来说,几何着色器的输入和输出都是图元,输入的图元是在应用程序阶段指定的,输出的图元可以在顶点着色器中实现。
3.4 Stream Output (Transform Feedback)
这是一个可选的阶段。这个阶段在DirectX中叫做Stream Output ,在OpenGL找叫做Transform Feedback。如果该阶段开启,那么顶点数据流会输出到一个Buffer中,这个Buffer可以给顶点着色器使用也可以返回给CPU,当前渲染管线则不会进行接下来的处理。
3.5 图元组装
这一步是将之前得到的顶点数据组合成图元,比如顶点图元、线段图元、三角形图元。该阶段输出图元进行接下来的处理。
3.6 透视除法和NDC裁剪
该阶段的输入是组装好的图元,输出的是NDC裁剪之后的图元。首先对图元的顶点进行透视除法,这样得到的顶点数据都会位于NDC内,方便进行NDC裁剪。图元裁剪后可以会产生新的图元。
3.7 屏幕空间映射
该阶段是将NDC下的图元顶点坐标映射到屏幕空间。值得注意的是顶点坐标是一个齐次坐标,透视除法后得到的是NDC下的坐标;然后,通过一个缩放和平移变换将x和y映射到屏幕空间。
3.8 面剔除 (Face Culling)
这一个阶段指的是三角形的前后面剔除。前或者后的定义是根据正视三角形的时候定义三角形顶点的旋向,可以定义逆时针旋转或者顺时针旋转为前面。实际上,面剔除跟实际的摄像机位置没有关系,不管摄像机转到哪个地方,前后面不会改变,比如渲染立方体的时候,后面都是立方体内部看不到的面,无论摄像机如何旋转。因为,前后面的定义是固定视角正对三角形时候定义的。
四、光栅化阶段
该大的阶段的输入是几何处理阶段输出的图元。该阶段主要分为四个部分,首先是光栅化图元得到片元(潜在的像素信息),然后进行Early Fragment Test,通过测试后再进行片元着色器,最终进行输出合并阶段的各种测试以及颜色混合等,再输出到颜色缓冲区。
4.1 图元光栅化
该阶段是将图元的顶点信息进行线性插值,然后生成片元数据。每个片元上有顶点信息线性插值而来的片元数据。需要注意的是,这个插值是线性的,如果有一些数据是非线性的,则不能在顶点着色器中计算然后输出到片元着色器,因为线性插值的结果和在片元着色器中计算的结果是不一致的。
这里需要特别说明的是,关于深度z’的生成。屏幕空间映射后的z’是关于摄像机空间z倒数的一个线性函数。之所以使用1/z而不是z,是为了在近处获得更好的深度缓冲精度,因为1/z在近处的变化更快,可以优化Z-Fighting这种现象。由于z’不是一个关于z的线性函数,因此z’应该是在光栅化后硬件自动根据1/z计算出来的,而不是先计算z’再光栅化。
4.2 Early Fragment Test
参考OpenGL的Early Fragment Test,可以看到不仅仅通常所说的Early Z-Test还有其它好几个阶段都可以进行EarlyTest,一共是四个测试(Pixel ownership test、Scissor test、
Stencil test、Depth test)和遮挡查询更新。根据文档,Pixel ownership test和Scissor test从OpenGL4.2起会总是在EarlyTest阶段进行。那么,如果这些测试没有在EarlyTest阶段进行,则会在最终的输出合并阶段进行;如果进行了,那么输出合并阶段也不会重复处理。
4.3 Early Z-Test的限制
不要在片元着色器中改变深度,比如glsl的gl_FragDepth;也不要discard片元,通常实现AlphaTest会根据Alphadiscard片元。因为这些操作会导致硬件无法预测最终的深度,从而无法进行提前深度测试。
4.4 片段着色器
片段着色器的输入是光栅化来的各种顶点属性,输出是一个颜色值。该阶段是计算光照结果的主要阶段。通常片元着色器会有比较复杂的计算,通常的优化手段是将计算转移到顶点着色器甚至CPU(应用程序阶段,用Uniform传入)上。
4.5 Output-Merger Stage(Raster Operations)
终于进入最后的输出合并阶段,该阶段的输入是一个个的片元。片元需要进行一些列的测试和转换,最终才会将颜色输出到缓冲区上。
Pixel ownership test
根据OpenGL的文档,该阶段只对默认缓冲区生效,用于测试像素是否被其它窗口遮挡的情形。对于自定义的FrameBuffer,不存在这个测试。
Alpha Test
需要特别说明的是,Alpha测试当前是已经被废弃了,从DirectX10和OpenGL3.1开始废弃,参考Transparency Sorting文档;当前需要在片元着色器用discard实现。列在这里主要是为了完整性。
Scissor test
参考OpenGL的剪切测试文档,Scissor Test。通过在应用程序阶段设置,可以让片元只通过视口的一个小矩形区域。根据EarlyTest的文档,推测该阶段目前都在EarlyTest阶段进行了。
Multisample operations
如果启用了MSAA,那么需要进行resolve才能够输出到默认颜色缓冲中,进行屏幕显示。假如在默认缓冲中开了MSAA,那么从MSAA的后备缓冲交换到前向缓冲就需要进行resolve操作,因为前向缓冲是single-sample的。如果是自定义的FrameBuffer开启了MSAA,那么在Blit到默认缓冲区的时候也需要进行resolve操作。
模板测试
模板测试基本思想是用一个八位的模板缓冲,一个参考值,一个比较函数,一个掩码,用该参考值和片元对应的模板缓冲值使用比较进行比较(比较之前进行掩码),通过的则片元可以继续进行深度测试,否则丢弃。另外还可以定义模板成功和失败,以及深度测试成功和失败后模板缓冲如何变化。可以参考OpenGL的Stencil Test文档。
模板测试的一个常见的应用是描边或者在像素级别分类。
深度测试
深度测试是根据当前片元的深度值与深度缓冲进行比较,比较函数可以设置,通过比较的片元才会进行接下来的处理,否则丢弃当前片元。
遮挡查询更新
参考OpenGL的遮挡查询文档Query Object。
该阶段会更新遮挡查询的结果,因此遮挡查询的结果只能用于下一帧渲染。
颜色混合
需要注意的是,容易误解半透明渲染才会有颜色混合,实际上颜色混合是管线的一个固定的阶段,不透明渲染也会有默认的混合方式。
理解颜色混合,首先要明白2个概念,source和dest,source指的是当前的片元,dest指的是要目标缓冲中对应的颜色。
颜色混合主要是需要设置2个函数,一个函数用于设置混合因子,一个函数用来设置混合函数。混合因子有四种,source rgb和dest rgb,source a和dest a,可以一起指定也可以分开指定。具体可以参考OpenGL的Blending文档。
sRGB转换
1、我们知道显示器或者颜色纹理的颜色空间是sRgb,sRGB空间就是Gamma校正的颜色空间,也就是已经Gamma校正过的颜色数据,这样子在显示器上才能正常显示。如果我们使用的线性工作流,也就是在线性空间中制作资源,编写Shader计算光照结果,那么片元着色器的输出需要转换到sRgb空间。这个转换部分硬件上是自动支持,对于不支持的硬件则需要在Shader里面转换。
2、如果要硬件自动转换,首先要创建的必须是srgb颜色空间的FrameBuffer,在OpenGL中可以使用glEnable(GL_FRAMEBUFFER_SRGB)开启;要保证片元输出的线性空间的颜色,也就是要采用线性工作流。
3、需要注意的是,避免将sRGB转换和ToneMaping混合起来,ToneMaping做的是将HDR映射到LDR。这只是一个带偏向性颜色范围映射,也就是算法倾向性的增强部分颜色。而sRGB转换才是将颜色从线性空间转换到sRGB空间。
Dithering
首先说明一下,颜色格式分为Float、Normalized Integer、Integer三种,默认缓冲区就是Normalized Integer格式的颜色。根据OpenGL的文档,当将一个Float颜色写入Normalized Integer缓冲区的时候,可以开启Dithering。Normalized Integer缓冲区是一个定点数缓冲来存储浮点值,比如通常我们的颜色是定义在[0,\1]的浮点值,但是颜色缓冲是[0,254]\的Int值,OpenGL会自动进行转换。
Logic operations
根据OpenGL的文档,当将颜色写入Integer(Normalized Or Not)缓冲区的时候,可以开启Logic operations。这是一些Bool操作。具体可以参考文档Logical Operation。Logical Operations在sRGB颜色空间是禁止的。
Write mask
该阶段可以分别指定Color、Depth、Stencil的写入掩码。具体参考文档Write Mask。
五、RenderPass
5.1 Renderer
以上所有内容在游戏引擎只是一个RenderPass,实际情况下,每帧游戏引擎会按照一定的顺序渲染多个Pass。比如,深度Pass(或者深度法线Pass)、阴影Pass、不透明物体Pass、透明物体Pass、后处理Pass等;而且后面的Pass会利用前面的Pass渲染结果来处理,比如深度Pass渲染的深度纹理可以用在后续的Pass实现一些效果。
总而言之,真实的游戏引擎是每帧渲染多个Pass,每个Pass对应上述的内容。
5.2 CameraStack
实际上,在Unity的Urp渲染管线中,更完整的过程是渲染相机堆栈->每个相机堆栈对应一个渲染器->每个渲染器包含多个Pass。不过,Urp里面每个相机堆栈只对应一个FrameBuffer,也就是所有的相机渲染输出都是这一个FrameBuffer,避免内存和带宽浪费。如果在场景内创建多个相机堆栈,那么其它的相机堆栈的输出应该是离屏RT。
六、参考资料
1、Graphics pipeline
2、Rendering Pipeline Overview
3、Per-Sample Processing
4、Output Merger (OM) stage
5、裁剪和空间管理
6、[总结] 漫谈HDR和色彩管理(三)SDR和HDR