filament 是Google开源的一个跨平台实时pbr渲染引擎。注意,这是一个渲染引擎,不是一个完整的游戏引擎。Filament Materials Guide ,pbr算法文档:Physically Based Rendering in Filament 。这些文档只是从使用层面简单介绍材质系统和使用的PBR算法等,并没有深入介绍材质的整体流程和一些关键技术细节。因此,本文打算深入介绍材质系统相关的整体流程以及材质渲染相关的关键技术细节。
一. 材质编写 这部分大概介绍下材质相关的语法。以下面的材质示例代码来说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 material { name : "Textured material", requires : [ uv0, color ], shadingModel : lit, blending : opaque, parameters : [ { type : sampler2d, name : baseColor }, { type : float, name : metallic }, { type : float, name : roughness } ], constants : [ { name : overrideAlpha, type : bool }, { name : customAlpha, type : float, default : 0.5 } ] } vertex { void materialVertex(inout MaterialVertexInputs material) { material.color *= sin(getUserTime().x); material.uv0 *= sin(getUserTime().x); } } fragment { void material(inout MaterialInputs material) { prepareMaterial(material); material.baseColor = texture(materialParams_baseColor, getUV0()); material.metallic = materialParams.metallic; material.roughness = materialParams.roughness; if (materialConstants_overrideAlpha) { material.baseColor.a = materialConstants_customAlpha; material.baseColor.rgb *= material.baseColor.a; } } }
从上述示例代码来看,一个材质分开三块:material、vertex、fragment。其中,material是材质熟悉块,vertex是顶点代码块,fragment是片元代码块。如果是一个compute材质,那么只有一个compute代码块。
1.1 材质属性块 这部分包括所有的材质设置,比如渲染状态设置、材质的uniform参数以及各种其它设置。举例说明,blending是混合模式,是渲染状态设置;shadingModel是光照模型,类似一个材质变体设置;parameters则是uniform参数,比如float最终是存放在材质的uniform buffer内,而sampler2d是生成uniform sampler。
1.2 代码块 filament的材质是一种surface材质。surface材质是一种受限制的材质,意思是一种只开放表面属性修改的材质,这种材质书写方式入门比较简单,但是功能比较受限制。unity的默认管线也支持surface材质,具体可以参考Introduction to surface shaders in the Built-In Render Pipeline 。
1.2.1 顶点代码 vertex下的入口函数是materialVertex,只能在该函数内修改inout的MaterialVertexInputs参数material来定制顶点着色器。MaterialVertexInputs是顶点的输入定义结构体,定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 struct MaterialVertexInputs { #ifdef HAS_ATTRIBUTE_COLOR vec4 color; #endif #ifdef HAS_ATTRIBUTE_UV0 vec2 uv0; #endif #ifdef HAS_ATTRIBUTE_UV1 vec2 uv1; #endif #ifdef VARIABLE_CUSTOM0 vec4 VARIABLE_CUSTOM0; #endif #ifdef VARIABLE_CUSTOM1 vec4 VARIABLE_CUSTOM1; #endif #ifdef VARIABLE_CUSTOM2 vec4 VARIABLE_CUSTOM2; #endif #ifdef VARIABLE_CUSTOM3 vec4 VARIABLE_CUSTOM3; #endif #ifdef HAS_ATTRIBUTE_TANGENTS vec3 worldNormal; #endif vec4 worldPosition; #ifdef VERTEX_DOMAIN_DEVICE #ifdef MATERIAL_HAS_CLIP_SPACE_TRANSFORM mat4 clipSpaceTransform; #endif // MATERIAL_HAS_CLIP_SPACE_TRANSFORM #endif // VERTEX_DOMAIN_DEVICE };
比如,color、uv0、uv1都是顶点属性。
1.2.2 片元代码 fragment也是类似的逻辑,入口函数是material,只能通过修改inout的MaterialInputs参数material来定制片元着色器。MaterialInputs结构体是pbr或者更复杂的渲染模型的属性,定义如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 struct MaterialInputs { vec4 baseColor; #if !defined(SHADING_MODEL_UNLIT) #if !defined(SHADING_MODEL_SPECULAR_GLOSSINESS) float roughness; #endif #if !defined(SHADING_MODEL_CLOTH) && !defined(SHADING_MODEL_SPECULAR_GLOSSINESS) float metallic; float reflectance; #endif float ambientOcclusion; #endif vec4 emissive; #if !defined(SHADING_MODEL_CLOTH) && !defined(SHADING_MODEL_SUBSURFACE) && !defined(SHADING_MODEL_UNLIT) vec3 sheenColor; float sheenRoughness; #endif float clearCoat; float clearCoatRoughness; float anisotropy; vec3 anisotropyDirection; #if defined(SHADING_MODEL_SUBSURFACE) || defined(MATERIAL_HAS_REFRACTION) float thickness; #endif #if defined(SHADING_MODEL_SUBSURFACE) float subsurfacePower; vec3 subsurfaceColor; #endif #if defined(SHADING_MODEL_CLOTH) vec3 sheenColor; #if defined(MATERIAL_HAS_SUBSURFACE_COLOR) vec3 subsurfaceColor; #endif #endif #if defined(SHADING_MODEL_SPECULAR_GLOSSINESS) vec3 specularColor; float glossiness; #endif #if defined(MATERIAL_HAS_NORMAL) vec3 normal; #endif #if defined(MATERIAL_HAS_BENT_NORMAL) vec3 bentNormal; #endif #if defined(MATERIAL_HAS_CLEAR_COAT) && defined(MATERIAL_HAS_CLEAR_COAT_NORMAL) vec3 clearCoatNormal; #endif #if defined(MATERIAL_HAS_POST_LIGHTING_COLOR) vec4 postLightingColor; float postLightingMixFactor; #endif #if !defined(SHADING_MODEL_CLOTH) && !defined(SHADING_MODEL_SUBSURFACE) && !defined(SHADING_MODEL_UNLIT) #if defined(MATERIAL_HAS_REFRACTION) #if defined(MATERIAL_HAS_ABSORPTION) vec3 absorption; #endif #if defined(MATERIAL_HAS_TRANSMISSION) float transmission; #endif #if defined(MATERIAL_HAS_IOR) float ior; #endif #if defined(MATERIAL_HAS_MICRO_THICKNESS) && (REFRACTION_TYPE == REFRACTION_TYPE_THIN) float microThickness; #endif #elif !defined(SHADING_MODEL_SPECULAR_GLOSSINESS) #if defined(MATERIAL_HAS_IOR) float ior; #endif #endif #endif #if defined(MATERIAL_HAS_SPECULAR_FACTOR) float specularFactor; #endif #if defined(MATERIAL_HAS_SPECULAR_COLOR_FACTOR) vec3 specularColorFactor; #endif };
因此,只需要简单的在入口函数内修改属性,就可以便捷的实现材质效果。
1.2.3 compute代码块 如果使用的是compute材质,那么代码块是compute代码块。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 material { name: testCompute, domain: compute, groupSize: [32, 32, 1], parameters: [ {type : sampler2d, name : color} ] } compute { void compute() { int3 id = int3(getGlobalInvocationID()); } }
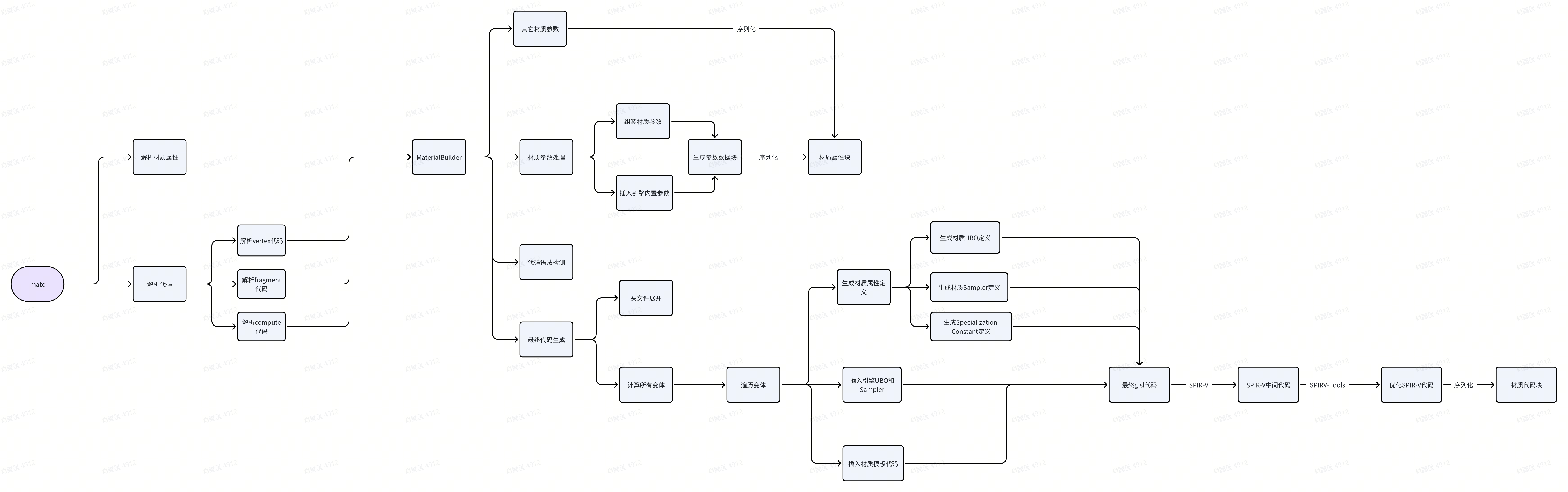
二. 材质编译 filament有一个专门的材质编译工具matc。该工具主要做了两件事情:一个是解析material材质属性块,根据材质属性块生成代码,需要序列化的材质属性写入材质属性数据块中;一个是编译材质代码,将编译后的所有的变体代码写入到代码数据块中。
2.1 材质属性编译 材质属性,指定是material块内的定义。材质属性主要包括两类,生成代码的属性和其它属性。生成代码的属性包括parameters和constants属性,parameters和constants属性会生成代码定义,同时也会进行序列化;而其它类型的材质属性会在解析后进行序列化。
2.1.1 parameters属性 parameters块内定义的属性,type指定类型,主要是两类:数值类型和采样器类型。最终,所有的数值类型会存放到一个着材质实例的uniform buffer内。而每个采样器类型的参数,都会生成一个着材质实例的uniform sampler。
2.1.2 其它属性 这部分属性包括,材质渲染状态设置、光照模型相关等。对于编译器来说,这部分设置解析出来后再序列化就行。
2.2 材质代码编译 2.2.1 生成材质属性定义 示例代码的parameters生成的ubo定义可能如下:
Uniform Buffer生成
1 2 3 4 layout(binding = 10, std140, set = 1) uniform MaterialParams { float metallic; float roughness; } materialParams;
Uniform Sampler生成
1 layout(binding = 10, set = 2) uniform lowp sampler2D materialParams_baseColor;
Specialization Constants生成
1 2 layout (constant_id = 8) const bool materialConstants_overrideAlpha = false; layout (constant_id = 9) const float materialConstants_customAlpha = 0.500000;
至于什么是specialization constants ,请参考文档:Utilizing Specialization Constants 。简而言之,这是一种将编译器的预处理阶段的宏延迟到gpu编译阶段的手段。
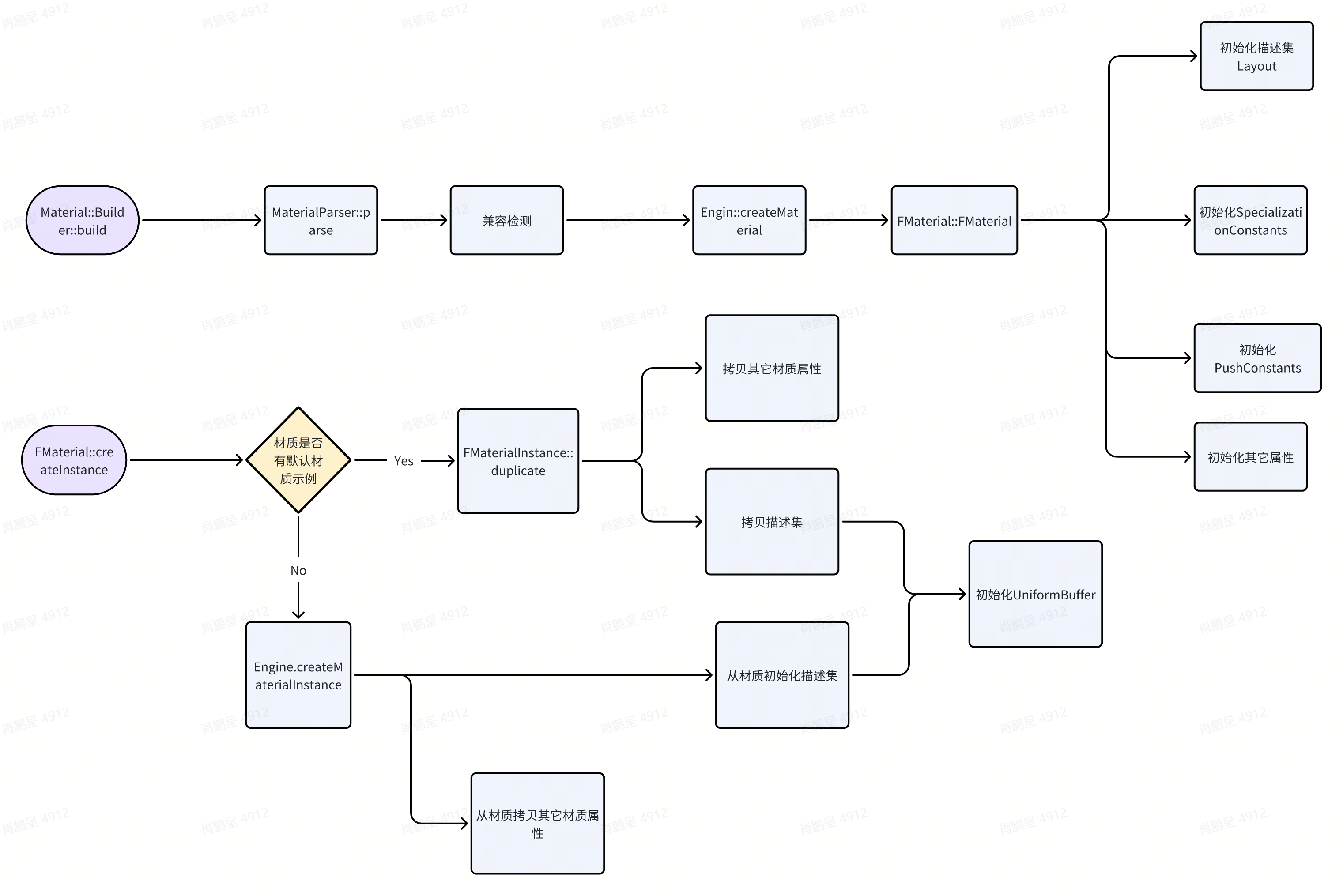
三. 材质加载和材质实例创建 3.1 整体介绍 这部分主要涉及三个类,材质类Material、材质示例类MaterialInstance、材质解析类MaterialParser。Material类对应的是Unity的Shader类,MaterialInstance类对应的是Unity的Material类。整体流程如下:
3.2 材质创建 3.2.1 数据解析
MaterialParser 兼容检测 3.2.2 创建材质对象 材质数据加载后,并且通过兼容性检测后,会调用engine的createMaterial函数去创建材质对象。filament的所有gpu相关对象最终都是通过engine类来创建管理的。3.2.3 初始化材质属性 在FMaterial类的构造函数内,会通过调用MaterialParser的具体解析函数,将所有材质数据属性解析出来,然后做好相应的运行时状态初始化。描述集Layout SpecializationConstants pushConstants 1 2 3 4 5 6 7 utils::FixedCapacityVector<filament::MaterialPushConstant> const PUSH_CONSTANTS = { { "morphingBufferOffset", filament::backend::ConstantType::INT, filament::backend::ShaderStage::VERTEX, }, };
其它属性 3.3 材质实例创建 创建材质实例有两种路径,但是初始化流程是一致的,都是初始化描述集和其它材质属性。初始化描述集 初始化其它材质属性
四. 材质变体 filament支持基于宏的传统变体,即每一个变体是一个gpu program。在编译材质时候,根据不同的宏定义组合编译出不同的gpu program;在运行阶段,根据stage和变体匹配到对应的gpu program。
4.1 变体定义 4.1.1 Surface材质变体 filament有一个Variant类,里面定义了Surface材质可以使用的变体。如下摘自其变体注释代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 // DIR: Directional Lighting // DYN: Dynamic Lighting // SRE: Shadow Receiver // SKN: Skinning // DEP: Depth only // FOG: Fog // PCK: Picking (depth variant only) // VSM: Variance shadow maps // STE: Instanced stereo rendering // // X: either 1 or 0 // +-----+-----+-----+-----+-----+-----+-----+-----+ // Variant | STE | VSM | FOG | DEP | SKN | SRE | DYN | DIR | 256 // +-----+-----+-----+-----+-----+-----+-----+-----+ // PCK // // Standard variants: // +-----+-----+-----+-----+-----+-----+-----+-----+ // | STE | VSM | FOG | 0 | SKN | SRE | DYN | DIR | 128 - 44 = 84 // +-----+-----+-----+-----+-----+-----+-----+-----+ // Vertex shader X 0 0 0 X X X X // Fragment shader 0 X X 0 0 X X X // Fragment SSR 0 1 0 0 0 1 0 0 // Reserved X 1 1 0 X 1 0 0 [ -4] // Reserved X 0 X 0 X 1 0 0 [ -8] // Reserved X 1 X 0 X 0 X X [-32] // // Depth variants: // +-----+-----+-----+-----+-----+-----+-----+-----+ // | STE | VSM | PCK | 1 | SKN | 0 | 0 | 0 | 16 - 4 = 12 // +-----+-----+-----+-----+-----+-----+-----+-----+ // Vertex depth X X 0 1 X 0 0 0 // Fragment depth 0 X X 1 0 0 0 0 // Reserved X 1 1 1 X 0 0 0 [ -4] // // 96 variants used, 160 reserved (256 - 96) // // note: a valid variant can be neither a valid vertex nor a valid fragment variant // (e.g.: FOG|SKN variants), the proper bits are filtered appropriately, // see filterVariantVertex(), filterVariantFragment().
8位变体
顶点和片元的变体是分开的
X表示该变体位可以切换,1或者0表示只能设置为固定值。
Reserved是无效的变体组合。4.1.2 PostProcess材质变体
1 2 3 4 5 6 7 8 static constexpr size_t POST_PROCESS_VARIANT_BITS = 1; static constexpr size_t POST_PROCESS_VARIANT_COUNT = (1u << POST_PROCESS_VARIANT_BITS); static constexpr size_t POST_PROCESS_VARIANT_MASK = POST_PROCESS_VARIANT_COUNT - 1; enum class PostProcessVariant : uint8_t { OPAQUE, TRANSLUCENT };
根据上述定义,后处理材质支持2个变体。
4.1.3 Compute材质变体 compute材质不支持变体切换。
4.2 变体编译
计算所有有效变体组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 // Generate all shaders and write the shader chunks. std::vector<Variant> variants; switch (mMaterialDomain) { case MaterialDomain::SURFACE: variants = determineSurfaceVariants(mVariantFilter, isLit(), mShadowMultiplier); break; case MaterialDomain::POST_PROCESS: variants = determinePostProcessVariants(); break; case MaterialDomain::COMPUTE: variants = determineComputeVariants(); break; }
determineSurfaceVariants函数是跟Variant类的定义,遍历出所有有效的顶点变体和片元变体。determinePostProcessVariants则是返回2个固定的顶点和片元变体。determineComputeVariants返回默认的一个0变体。
根据变体组合生成宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void ShaderGenerator::generateSurfaceMaterialVariantDefines(utils::io::sstream& out, ShaderStage stage, MaterialBuilder::FeatureLevel featureLevel, MaterialInfo const& material, filament::Variant variant) noexcept { bool const litVariants = material.isLit || material.hasShadowMultiplier; CodeGenerator::generateDefine(out, "VARIANT_HAS_DIRECTIONAL_LIGHTING", litVariants && variant.hasDirectionalLighting()); CodeGenerator::generateDefine(out, "VARIANT_HAS_DYNAMIC_LIGHTING", litVariants && variant.hasDynamicLighting()); CodeGenerator::generateDefine(out, "VARIANT_HAS_SHADOWING", litVariants && filament::Variant::isShadowReceiverVariant(variant)); CodeGenerator::generateDefine(out, "VARIANT_HAS_VSM", filament::Variant::isVSMVariant(variant)); CodeGenerator::generateDefine(out, "VARIANT_HAS_STEREO", hasStereo(variant, featureLevel)); switch (stage) { case ShaderStage::VERTEX: CodeGenerator::generateDefine(out, "VARIANT_HAS_SKINNING_OR_MORPHING", hasSkinningOrMorphing(variant, featureLevel)); break; case ShaderStage::FRAGMENT: CodeGenerator::generateDefine(out, "VARIANT_HAS_FOG", filament::Variant::isFogVariant(variant)); CodeGenerator::generateDefine(out, "VARIANT_HAS_PICKING", filament::Variant::isPickingVariant(variant)); CodeGenerator::generateDefine(out, "VARIANT_HAS_SSR", filament::Variant::isSSRVariant(variant)); break; case ShaderStage::COMPUTE: break; } }
所有的宏定义组合就对应一个变体组合的program。
4.3 变体切换 变体编译阶段是根据材质类型、Stage(顶点/片元)、变体组合来生成对应的program的。因此,变体切换阶段,也是根据这些信息查找出对应的program代码。然后,使用这个代码(比如SPIR-V中间代码)来创建gpu program。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void FMaterial::prepareProgramSlow(Variant variant, backend::CompilerPriorityQueue priorityQueue) const noexcept { assert_invariant(mEngine.hasFeatureLevel(mFeatureLevel)); switch (getMaterialDomain()) { case MaterialDomain::SURFACE: getSurfaceProgramSlow(variant, priorityQueue); break; case MaterialDomain::POST_PROCESS: getPostProcessProgramSlow(variant, priorityQueue); break; case MaterialDomain::COMPUTE: // TODO: implement MaterialDomain::COMPUTE break; } } bool MaterialChunk::getBinaryShader(BlobDictionary const& dictionary, ShaderContent& shaderContent, ShaderModel shaderModel, filament::Variant variant, ShaderStage shaderStage) { if (mBase == nullptr) { return false; } uint32_t key = makeKey(shaderModel, variant, shaderStage); auto pos = mOffsets.find(key); if (pos == mOffsets.end()) { return false; } shaderContent = dictionary[pos->second]; return true; }
getSurfaceProgramSlow最终会调用到MaterialChunk::getBinaryShader从二进制材质数据中查找出指定变体的二进制代码。makeKey函数的参数是shaderModel(平台)、variant、shaderStage,这个key就是变体查找的键值。
4.4 变体使用 filament的变体使用方式分为三步:
计算变体组合 prepareProgram
1 2 3 4 5 6 void prepareProgram(Variant variant, backend::CompilerPriorityQueue priorityQueue = CompilerPriorityQueue::HIGH) const noexcept { if (UTILS_UNLIKELY(!isCached(variant))) { prepareProgramSlow(variant, priorityQueue); } }
getProgram
1 2 3 4 5 6 backend::Handle<backend::HwProgram> getProgram(Variant variant) const noexcept { assert_invariant(mCachedPrograms[variant.key]); return mCachedPrograms[variant.key]; } pipeline.program = ma->getProgram(info.materialVariant);
然后将获得的program赋值给pipeline的program。
4.5 再谈SpecializationConstants变体 4.5.1 filament变体的问题 根据前述变体使用的步骤,在使用filament的变体时候并不方便。
1. 首先,变体设置是需要在外部计算的。
2. 其次,变体设置并没有保存在材质实例内,反而需要外部代码保存。
3.从使用角度上来说,应该在材质实例内保存其对应的variant,然后一个材质实例对应一个program才更方便理解。
4.5.2 filament的SpecializationConstants变体问题 filament的specializationConstants变体也存在类似的问题。specializationConstants变体是通过传入设置数据给gpu program对象来生效的,而且specializationConstants变体的设置还存在在材质内。
4.5.3 优化思路 因此,比较好的优化方向是将variant和specializationConstants的状态都保存在材质实例内;然后,通过材质实例来从材质中获得不同的program和设置不同的specializationConstants数据。
五. 渲染数据的提交和绑定 最后再来讲一讲渲染使用的数据提交和绑定。渲染数据一般指定是Buffer和Sampler,也包括其它一些特殊数据,比如SpecializationConstants和pushConstants。从作用范围上来区分,渲染数据一般能分为三个级别,渲染当前pass要使用的全局数据、当前使用材质的数据、当前drawcall对应的物体的数据。
5.1 渲染Pass数据提交和绑定 通常是封装一个Pass级别的数据提交类,比如ColorPassDescriptorSet、PostProcessDescriptorSet、SsrPassDescriptorSet。这些类里面有一个DescriptorSet对象用于真正的数据提交和绑定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class PostProcessDescriptorSet { public: explicit PostProcessDescriptorSet() noexcept; void init(FEngine& engine) noexcept; void terminate(HwDescriptorSetLayoutFactory& factory, backend::DriverApi& driver); void setFrameUniforms(backend::DriverApi& driver, TypedUniformBuffer<PerViewUib>& uniforms) noexcept; void bind(backend::DriverApi& driver) noexcept; DescriptorSetLayout const& getLayout() const noexcept { return mDescriptorSetLayout; } private: DescriptorSetLayout mDescriptorSetLayout; DescriptorSet mDescriptorSet; }; void PostProcessManager::setFrameUniforms(backend::DriverApi& driver, TypedUniformBuffer<PerViewUib>& uniforms) noexcept { mPostProcessDescriptorSet.setFrameUniforms(driver, uniforms); mSsrPassDescriptorSet.setFrameUniforms(uniforms); } void PostProcessManager::bindPostProcessDescriptorSet(backend::DriverApi& driver) const noexcept { mPostProcessDescriptorSet.bind(driver); }
后处理Pass会在适当的时候调用相关函数进行数据提交和绑定,一般是在Pass的最开始进行设置。
1 2 3 4 5 6 7 8 void FRenderer::renderJob(RootArenaScope& rootArenaScope, FView& view) { FEngine& engine = mEngine; JobSystem& js = engine.getJobSystem(); FEngine::DriverApi& driver = engine.getDriverApi(); PostProcessManager& ppm = engine.getPostProcessManager(); ppm.setFrameUniforms(driver, view.getFrameUniforms()); ... }
5.2 材质数据提交和绑定 所有的渲染Pass都必须使用材质,渲染物体的Pass需要切换材质,后处理Pass则是使用一个材质。材质数据的使用也是需要有时机的。材质数据实际上会覆盖Pass级别的数据的设置,如果有重复的话;不过,按照filament的定义,这两部分数据是不会互相影响的,因为使用的是不同的DescriptorSetLayout。实际上,filament定义pipeline里面已经对PerView和PerMaterial的DescriptorSetLayout做了区分。PerView的layout就是前面所说的渲染Pass级别的数据。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 struct PipelineLayout { using SetLayout = std::array<Handle<HwDescriptorSetLayout>, MAX_DESCRIPTOR_SET_COUNT>; SetLayout setLayout; // 16 }; struct PipelineState { Handle<HwProgram> program; // 4 Handle<HwVertexBufferInfo> vertexBufferInfo; // 4 PipelineLayout pipelineLayout; // 16 RasterState rasterState; // 4 StencilState stencilState; // 12 PolygonOffset polygonOffset; // 8 PrimitiveType primitiveType = PrimitiveType::TRIANGLES; // 1 uint8_t padding[3] = {}; // 3 }; static constexpr size_t MAX_DESCRIPTOR_SET_COUNT = 4; // This is guaranteed by Vulkan. enum class DescriptorSetBindingPoints : uint8_t { PER_VIEW = 0, PER_RENDERABLE = 1, PER_MATERIAL = 2, }; 在RenderPass执行时候渲染Command时候,给pipepline同时绑定PER_VIEW和PER_MATERIAL的layout。 // Each material has its own version of the per-view descriptor-set layout, // because it depends on the material features (e.g. lit/unlit) pipeline.pipelineLayout.setLayout[+DescriptorSetBindingPoints::PER_VIEW] = ma->getPerViewDescriptorSetLayout(info.materialVariant).getHandle(); // Each material has a per-material descriptor-set layout which encodes the // material's parameters (ubo and samplers) pipeline.pipelineLayout.setLayout[+DescriptorSetBindingPoints::PER_MATERIAL] = ma->getDescriptorSetLayout().getHandle(); 5.2.1 材质commit数据 void FEngine::prepare() { FEngine::DriverApi& driver = getDriverApi(); for (auto& materialInstanceList: mMaterialInstances) { materialInstanceList.second.forEach([&driver](FMaterialInstance* item) { item->commit(driver); }); } } void PostProcessManager::commitAndRenderFullScreenQuad(backend::DriverApi& driver, FrameGraphResources::RenderPassInfo const& out, FMaterialInstance const* mi, PostProcessVariant variant) const noexcept { mi->commit(driver); mi->use(driver); FMaterial const* const ma = mi->getMaterial(); PipelineState const pipeline = getPipelineState(ma, variant); assert_invariant( ((out.params.readOnlyDepthStencil & RenderPassParams::READONLY_DEPTH) && !pipeline.rasterState.depthWrite) || !(out.params.readOnlyDepthStencil & RenderPassParams::READONLY_DEPTH)); driver.beginRenderPass(out.target, out.params); driver.draw(pipeline, mFullScreenQuadRph, 0, 3, 1); driver.endRenderPass(); } void FMaterialInstance::commit(DriverApi& driver) const { // update uniforms if needed if (mUniforms.isDirty()) { driver.updateBufferObject(mUbHandle, mUniforms.toBufferDescriptor(driver), 0); } // Commit descriptors if needed (e.g. when textures are updated,or the first time) mDescriptorSet.commit(mMaterial->getDescriptorSetLayout(), driver); }
prepare是在FRenderer::beginFrame里面调用的,即每帧开始时候会提交所有的材质实例数据,实际上这里主要是非处理材质,后处理材质是在commitAndRenderFullScreenQuad内提交的。commit内做了两件事情,一个是更新UBO数据,一个是通过DescriptorSet进行commit。
5.2.2 材质绑定数据 绑定材质数据是通过调用材质实例的use函数。材质绑定数据要在调用drawcall函数之前,比如renderpass里面就必须在执行每个command的drawcall前绑定,后处理这种Pass则需要在最终执行渲染drawcall之前绑定数据,可以参考commitAndRenderFullScreenQuad函数代码。下面代码段是RenderPass内绑定材质数据的代码:
1 2 3 4 5 6 7 8 9 if (UTILS_UNLIKELY(mi != info.mi)) { // this is always taken the first time assert_invariant(info.mi); mi = info.mi; ... // Each MaterialInstance has its own descriptor set. This binds it. mi->use(driver); }
上述代码在RenderPass::Executor::execute内执行command的一段,可以看到在材质实例变化时候,会调用材质实例的use函数绑定不同的材质级别数据。
5.3 Renderable数据提交和绑定 同一个渲染Pass的Command,可以包括多个材质实例;同一个材质实例,可以渲染多个物体。因此,物体级别的数据优先级别是最高的。
5.3.1 初始化Renderble数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct PrimitiveInfo { // 56 bytes union { FMaterialInstance const* mi; uint64_t padding; // make this field 64 bits on all platforms }; backend::RenderPrimitiveHandle rph; // 4 bytes backend::VertexBufferInfoHandle vbih; // 4 bytes backend::DescriptorSetHandle dsh; // 4 bytes uint32_t indexOffset; // 4 bytes uint32_t indexCount; // 4 bytes uint32_t index = 0; // 4 bytes uint32_t skinningOffset = 0; // 4 bytes uint32_t morphingOffset = 0; // 4 bytes backend::RasterState rasterState; // 4 bytes uint16_t instanceCount; // 2 bytes [MSb: user] Variant materialVariant; // 1 byte backend::PrimitiveType type : 3; // 1 byte 3 bits bool hasSkinning : 1; // 1 bit bool hasMorphing : 1; // 1 bit bool hasHybridInstancing : 1; // 1 bit uint32_t rfu[2]; // 16 bytes }; static_assert(sizeof(PrimitiveInfo) == 56); struct alignas(8) Command { // 64 bytes CommandKey key = 0; // 8 bytes PrimitiveInfo info; // 56 bytes };
如上代码,RenderPass内的Command定义内有一个图元信息结构PrimitiveInfo。该结构内有一个backend::DescriptorSetHandle成员dsh。dsh表示的就是Renderable级别的渲染数据。dsh是在RenderPass::generateCommandsImpl内通过场景数据FScene::RenderableSoa内的FScene::DESCRIPTOR_SET_HANDLE数据初始化的。
5.3.2 绑定Renderble数据 在执行每个command的drawcall之前,会调用driver.bindDescriptorSet绑定Renderable级别的数据。
1 2 3 driver.bindDescriptorSet(info.dsh, +DescriptorSetBindingPoints::PER_RENDERABLE, {{ offset, info.skinningOffset }, driver});
5.4 其它数据 5.4.1 SpecializationConstants 这部分之前提过,filament是通过切换变体时候,将材质内保存的constants设置数据传递给gpu program,也提到过这部分在实现上有一定的不合理。
5.4.2 PushConstant 1 2 3 4 5 if (UTILS_UNLIKELY(info.hasMorphing)) { driver.setPushConstant(ShaderStage::VERTEX, +PushConstantIds::MORPHING_BUFFER_OFFSET, int32_t(info.morphingOffset)); } driver.draw2(info.indexOffset, info.indexCount, info.instanceCount);
pushConstant数据则是在调用drawcall之前通过driver.setPushConstant传入driver。目前,filament只支持固定的pushConstants数据。