一直以来都默认删除指针前,都得判断下是否是空指针。直到最近在看More Effective C++
的时候,作者明确指出了C++在语言层次上保证删除空指针是安全的,我才意识到这个问题。
我用vs2013实践了下,发现没有运行错误。所以了,这大概是从学习C语言起遗留下来的思维
定势吧。以前用C调用malloc申请内存的时候,对应的是free释放,free肯定是不能释放NULL指针的,所以
自然而然就觉得delete也不能处理NULL指针。
虽然说,这件事情无伤大雅,但是确实没必要在delete之前判断下是否为NULL了,毕竟自己
判断和编译器判断都是一样的结果,也不存在什么效率问题。
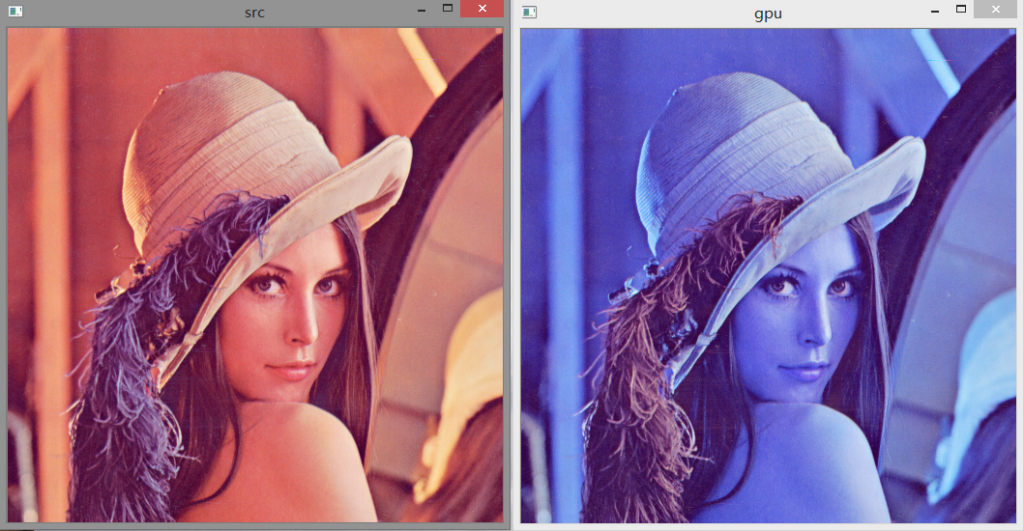
vs2013下配置cuda6.5和opencv2.4.10的gpu版本
首先,当然是安装好vs2013。第二步是配置最新的cuda6.5版本,这个有相关的教程。
这里要讲的是如何生成相应的opencv的gpu版本。
首先,当然是去opencv官方网站下载opencv,然后解压到指定的目录,最好不要出现
中文路径,因为后面需要用到cmake。2.4.10的下载地址,已经不好找了。最新的是3.0beta版本,
由于模块分类完全变了,所以还是别去吃螃蟹了。
下载好解压之后,会出现两个子目录,build和source。如果,你只使用cpu版本,那么build
里面的内容就满足你的要求了。否则,打开source目录,你会发现有一个CMakeLists.txt文件。
那么,肯定是需要使用cmake生成相应的工程了。
第二步,下载cmake,安装好cmake。
第三步,用cmake生成工程。操作方法:假如opencv在f盘根目录下面,那么设置好cmake的
source目录和build目录。然后点击configure按钮,选择对应的平台如visual studio 12。注意,现在
记得选择WITH_CUDA,WITH_CUFFT,WITH_CUBLAS等相关的选项。
然后,点击generate按钮就能生成对应的工程。如果,出现配置错误,可以根据cmake的
提示寻找原因。基本上是些环境变量的设置问题,或者是平台不匹配等。
如图所示:

注意build目录不用和source目录设置为同一个,否则可能引起问题,cmake也会出警告。
第四步,就是打开工程生成文件了。用vs2013或者你的使用版本,打开build目录下的OpenCV.sln
文件。最简单的办法,就是批生成->全选->重新生成。
关键的问题出现,如果你只是这样做,可能有几个dll无法编译出来,比如说opencv_gpu2410.dll。
问题在哪里了。我试验了好几次,每次几个小时,都是这样的结果。顿时觉得很郁闷,
只能去分析vs的输出内容了。突然发现有个错误提示:大致内容是NCV.cu文件中的std::max没有
定义。这个cu文件在..\opencv\sources\modules\gpu\src\nvidia\core下面。
你最后需要做的就是打开这个文件,然后包含algorithm头文件就行了,然后再重新编译吧。
PS:我只生成过32平台下的gpu版本了,64位的就没有去尝试了。
opencv gpu或者cuda加速第一次调用
经测试,第一次gpu调用,无论是用opencv的gpu模块或者cuda都会比较耗时,可能将近1s。
额,这也不是我一个人碰到的问题,确实有这回事。stackoverflow上面有个帖子就是关于这个的。
帖子地址:关于速度慢,关于解决办法。
如果,看了上面的帖子话,这篇文章也不用看下去了。因为我要讲的就是这件事情。
我的观点也是,在第一次调用之前先建立cuda context。为什么需要做这样的事情了?额,假如,
你只调用一次gpu处理,总不能太慢了吧。那样就看不到速度了,所以先调用次垃圾操作初始化cuda环境。
方法是调用cudaFree(0),在这之前最好调用先调用cudaSetDevice(0)。记住包含cuda的头文件,
如果只有opencv的头文件,这2个函数是找不到的。还有,建立的工程是cuda runtime模版。
在我的L0Smooth代码里,这样的处理之后,初次L0Smooth调用能减少1s左右,从3s变成了2s。
其余的耗时,基本都在gpu版本的dft和idft,还得继续寻找加快速度的办法。
opencv的gpu部分实现dft
最近打算使用gpu优化L0Smooth的代码,但是不熟悉opencv的gpu部分的使用,
直接用cuda觉得太麻烦,还是继续试试opencv吧。
首先,从网站上下载下来的默认版本是不支持gpu的,必须下载代码下来,用cmake生成工程,注意
选择支持cuda等选项,具体参考教程。这样生成的版本才能支持gpu运算。
那么如何测试自己的opencv是否支持gpu计算了,以及自己的硬件是否符合要求?
使用这句代码打印cuda设备个数:
printf(“Device Num:%d\n”, cv::gpu::getCudaEnabledDeviceCount());
如果,个数大于0,那么说明你的显卡是支持cuda的,并且你的opencv版本支持gpu运算了。
下面是我测试成功的gpumat实现的dft和idft函数,输入和输出的都是cpu上的mat。
1 | void Dft(cv::Mat in, cv::Mat out) |
从代码上,可以看出,要尽可能把运算放到gpu上去,包括很多辅助运算,比如说merge,convert等可以加快速度。
这个版本的代码,dft的输入和输出都是双通道的,也就是一个通道实数,一个是复数的矩阵。通过merge生成和split分离。
这两个函数在分离通道单独处理时候非常有用,比如说可以分离彩色图像的三个通道,单独进行dft处理。最后再将结果合并。
opencv实现快速傅立叶变换和逆变换
说实话觉得网上很多人转载的文章的挺坑的,全部是opencv文档程序的翻译,看来看去都是那一
篇,真的没啥意思。文档的地址。
本来opencv实现dft就是一个函数的事情,但是很少有关于逆变换使用的资料。我这几天在翻译
matlab版本的L0Smooth到opencv上面,就碰到这样一件很坑爹的事情。
首先,很少有人说清楚这个函数的使用方法。还有,根据教程,dft之前最好扩充原矩阵到合适的尺
寸(2,3,5的倍数),再调用dft会加快速度。那么,idft的时候了?如何恢复原有的尺寸?
在我的L0Smooth代码里,就碰到这样的事情了。如果,图片尺寸是2,3,5的倍数,那么能够得到
正确结果。否则得到是全黑的图片。如果,我不扩张矩阵,那么就能正确处理。
所以,到这里,我不推荐调用dft之前先扩充矩阵了。因为,我找了很久也没找到解决办法。
我数学水平有限,也分析不出原因,也没有时间去系统的学习这些了。
这里提供两个例子,说明dft和idft的使用。
例子一:类似于opencv官方文档的例子
1 | #include "opencv2/core/core.hpp" |
代码意思很简单,dft之后再idft,注意参数额,必须有DFT_SCALE。代码中,先merge了个
复数矩阵,在例子2中可以看到,其实这一步可以去掉。
例子2:
1 | #include "opencv2/core/core.hpp" |
从代码中可以看到,dft时候添加参数DFT_COMPLEX_OUTPUT,就可以自动得到复数矩阵了,代码更加简洁。
注意,必须先将图片对应的uchar矩阵转换为float矩阵,再进行dft,idft,最后再转换回来。
cuda结合opencv实现简单的平滑滤波
这次也是使用opencv的mat加载处理图像。唯一与上次有区别的是核函数的编写。
根据cuda的线程分配模型,每一个像素是分配单独的线程处理的。那么有这样的一个疑问?
像平滑滤波这些应用,如何在每一个线程中获取周围的像素了?
其实,这个问题很好解决。因为,在核函数中,我们能够根据线程id,块id,块尺寸等计算
出当前像素的位置。那么,自然能够得到其邻域的位置。从而实现了平滑滤波。
代码如下:
1 | #include <stdlib.h> |
效果如图:
cuda和opencv混合使用
这里我既不介绍opencv的基本使用,也更加不会介绍cuda的使用。推荐下cuda的一本书:GPU高性能编程CUDA实战。
opencv这么强大的工具不用肯定是浪费了,opencv也有gpu的部分,据说也是用cuda实现的,但是灵活性肯定不如直接用cuda吧。
所以,我觉得只需要使用opencv负责cpu的部分,比如加载图片,gui之类的,而cuda负责并行的处理。还有,本着方便的原则,
opencv使用cpp的版本,不想再去管内存分配释放了。虽然,Mat相对来说更难使用。
下面是一个简短的交换rb通道的cuda和opencv混合的程序。
1 | #include <stdlib.h> |
运行效果:
opencv部分不用做过多解释了,cuda的那些内存操作函数也不用解释。唯一需要解释的是核函数里面的这两句:int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;千万别搞错x和y,否则效果就完全不对了。根据cuda的模型,线程是一块一块的。一个线程块里面有很多线程,那么如何索引这些线程了?
把线程块看作是是三维的(一般用到一维或者二维)数组,然后根据数组索引得到具体线程。至于blockDim指的是一共有多少线程块了,这个也是三维的,意思一个gpu格子里面,
会出现三维的线程块组合。gpu格子的大小,在cuda里面用gridDim指代。所以,从上到下就是三层模型吧,三维的grid->三维的block->三维的thread。具体的理解,参照书籍或者教程吧。
vs2013下设置cuda高亮
因为是最近才接触cuda,安装的是6.5版本,所以网上的教程都不是完全适用了。
总之,设置高亮大致分为四步,不限于vs2013,其他平台下也类似。
第一步,是在vs2013里面设置vc++文件支持.cu;cuh;文件。方法:工具->选项->文本编辑器->文件扩展名。
得到如图所示的界面:注意,在右侧可以添加vc++类型的文件扩展名,这是我的设置效果,操作就不用细说了。
第二步,是设置visual assist的目录。在va的C++directory里面,选择custom选项,然后包含你的cuda的sdk目录,效果如图:
第三步,是设置va的支持文件类型,类似于第一步。但是,这次是修改注册表的值。注册表目录:
HKEY_CURRENT_USER/Software/Whole Tomato/Visual Assist X/VANet12,修改属性ExtSource的值为:.c;.cpp;.cc;.cxx;.tli;.cu;.cuh;
意思就是添加上cuda的头文件和源文件类型,vs2010的改法类似。
第四步,完成以上步骤之后,还可能会发现一些内置变量下面是有波浪线的。怎么办了?
加上这句:#include “device_launch_parameters.h”,就行了。cuda 6.5估计把内置变量的声明放在该头文件下面了吧。
最终的效果:
main函数返回,exit,abort
最近在看C++标准程序库,看到介绍这两个函数的地方,记起来刚上大学的时候用exit结束
程序。那个时候什么都不懂,程序能运行就行了。不过,也好奇过这些东西,到底有什么区别了。
书上说的很简单,exit会释放static对象(当然包括全局对象,函数static对象,类的static对象),
清空缓冲区,关闭io,然后终止程序(如果atexit有登记函数,那么执行这些函数)。
abort则真的是什么都不干,就退出来了。
以上两者都没有解栈(stack unwinding),也就是栈里面的变量没有析构。这个只有从main函数返回才会正常解栈。
那么,考虑这样的一个问题,既然程序都要结束了,这些操作到底有没有区别了。进程介绍了,
所有的资源都是还给操作系统了吧。只是从程序设计角度来说,资源还是应该由申请者释放的,个人是从这个角度看的。
找工作的经历
工作其实早就确定了,三方也接受入库了。成埃落定,也是时候扯两句了。
由于以前没打算去工作,所以就没参加实习的校园招聘。暑假7月份尝试找了一次实习,没成功。校园招聘面试了四家,拿到了两家。
找工作的时候,也看了一些别人的面经,抱着回馈社会的想法,也写写我碰到的问题。虽然三言两语很难描述清楚,权当随便扯扯吧。
第一家,2014.7月,AMD实习,结果:经理面没通过
参加的原因也莫名其妙,七月初,论文投出去了,导师给我发了个AMD科研小组实习招聘消息,我本着试一试的态度就试一试了。
1.科研小组实习面试
人家本来要的就是去做科研的,所以要求里面最好是发了文章,最好是博士生,硕士生也考虑。反正,当时我是做了英文版的简历投过去了。
过了几天hr确定电话面试的时候,那个小组的负责人就给我电话面试了。
大致问题:科研项目,C++(虚函数,多态),算法(链表有环,数组中出现一次的数字,其余出现两次),图形学(居然问我基本算法细节,只能说我简历写偏差了)。
大致就是问的这些吧,时间久了,也回忆不起来了。基本当然是最重要的,我暑假还没开始准备工作,所以也答得不怎么样。结果当时没有通过,虽然感觉面试官很热情,很有可能,
然后非常感谢他把我的简历给了驱动开发小组,所以我后面还有次机会。
2.OpenGL驱动开发小组面试
1>1面:一面的面试官好喜欢聊,巴拉巴拉的说了一大堆。我还是分块回忆下吧。C++(vector和list的使用场合,map的实现),体系结构(cpu缓存更新算法),操作系统(用户态和内核态区别),
算法(快排),OpenGL(glsl常用细节,VBO)等等。
2>2面:二面面试官打电话一开始就跟我说一面反应非常好,也许是和一面面试官聊得很投缘吧,然后他要来确认下。所以,他就继续问了。大致问题:项目相关的东西,其余的和一面的差不多,
主要是根据简历问了下,记不起来了。
3>3面经理面试:这次谈了好久,问题也问了很多,也说到以后实习的细节,但是我最终还是傻逼了,经理问我,如果AMD给我offer,问我怎么选,我说我现在还不清楚,
还没考虑这件事情,然后是双方沉默了一会儿。最终估计是他们考虑到我从长沙去上海的成本问题,以及中途必须去参加校招耽误时间等等,就不搭理我了,也算是客气的拒绝吧。
问题也问了很多,以项目和图形学为主。图形学(OpenGL光照模型,VBO,normal map),界面(MFC/QT熟悉程度),其余大致和前面的差不多。主要是时间长了,记不起来了。
第二家,2014.9月,阿里巴巴,结果:一面挂了
通过这次面试,我终于感受到了阿里的火爆程度和神奇程度。本来就打算去做游戏的,所以也没不是很在意结果,只是跑了一次武汉,等了那么久。
阿里是在线笔试,通过的人比较多。记得笔试题里面有个dp的最长连续子串。
从长沙跑去武汉,住了一晚。我选了11点的时间,但是9点多去的,结果一直在那里等,问了无数次hr,一直是再等15分钟,结果就真的等到11点了。
好吧,终于能够面试了。我面的方向是C++,但是一进去发现面试官的桌子上摆着java的牌子。无所谓了,开始面吧。
面试题目:C++(野指针有哪些情况,内存泄漏,怎么理解面向对象),数据结构和算法(B树,B+树,还有个简单的手写算法题,忘记了),操作系统(进程和线程的区别),
其余的就是我简历上的科研项目,
说了一大堆,自我感觉良好了,感觉面试官也有兴趣。只是最后,他问了句,你对互联网其他的方向了解不,我说不了解,听说过大数据什么的,然后就让等消息去了。
坐在外面等了一会儿,就有通知说你可以回去等消息了,意思是你玩完了。后面才知道,我和同学是同一个面试官一面刷的,他也是面c++,然后两个人还问了类似的题目,
只是刷的莫名其妙的。。。好吧,就这样吧。
第三家,2014.9月,腾讯游戏,结果:终于拿到offer了
只能说幸福来的太突然。阿里挂了之后,就和同学去找另外的同学了。他们要去华科参加腾讯笔试,我腾讯选的地点是长沙,所以不怎么想笔试了。但是,既然来了就去霸笔下吧。
腾讯笔试的选择题范围比较广,也很基础,大家学好基础就什么都不怕了。大题一个进制转换,还有个进程通信,还有个好像是ios的。
说说面试吧。笔试完了之后就回长沙了,也没报希望,毕竟是霸笔的。大概是17号半夜1点多给我发的短信和邮件,呵呵,我早上9点多一到实验室才发现。hr工作时间挺晚的额,
让我10点钟赶到武汉面试,这是不可能的。然后,我就咨询同学怎么办,有人说打电话问,有人说发邮件问。我就抱着试一试的态度,发邮件到校招邮箱说明了情况。腾讯的效率真高,马上就有hr
打电话问我了。然后,商量好时间调到下午2点。唉,既然说话了,我只能再次踏上去武汉的征途了。
一面:两点多才赶到地点,找到之后去大厅问问,还以为我错过时间了,hr打电话问面试官,然后就让我马上去房间面试了。一面的估计是小boss。我说明了下从长沙赶来的情况,
面试官表示清楚,然后就开始面试了。题目:话说我记得的不多了,智力题(分油,这类题大家可以好好学学,我没做出来,我只是提出可以用搜索状态解决,然后面试官说不用这么麻烦,
让我再想,只是没思路了),算法题(有序数组构建搜索二叉树),图形学(直线和球求交点),其余的,我确实记得不清楚了。。。最后问了下,我这几年碰到什么过不去的难事没,
还有工作地点的倾向。然后面试官直接让我拿着草稿纸去二面面试官的房间了。
二面:二面感觉也是大boss了。二面问的问题更多,一开始是针对我的简历问我的科研项目,讲了好多,感觉面试官很多东西也懂,一直到后面问到无法问了,才问其他内容。
图形学(渲染管线,ogl或者dx都行,点关于平面对称点怎么求),智力题(显示读数的称,一次称重,区分不同的堆,具体的忘记了),算法题(用尽可能少的队列实现一个栈),C++(static的
用法,异常的初次处理和二次处理的区别),大概就这些吧,很多也忘记了。面试官人挺好的,给我安排第二天最早的hr,非常感谢额。
三面:第二天9点的hr面,基本上是自我介绍,然后问了我一个关于逻辑的智力题(如何处理城市拥堵与汽车发展的矛盾)。然后谈谈对腾讯氛围的感受之类的,问问就业地点意向。
回到长沙之后收到电话通知了,确认知道是一个游戏工作室,虽然在二面时候也询问了。再次感谢面试官的照顾,让我不用在武汉呆那么久。
第四家,2014.9月,美团网,结果:拿到offer
在学校参加了美团的笔试和面试,过程挺顺利的。美团笔试毕竟变态,全部是写代码的大题,貌似大家也就能写完几个,时间也就90分钟。面试是在学校的一间教室。
一面、二面、三面,都是在教室一上午面完的,挺累的。
一面:先是问简历,问得比较详细,甚至到一些实现细节,这个得准备充分。算法(一个大数组找出一个重复出现的数字),操作系统(程序的堆和栈等信息,进程和线程的区别),
网络(四次挥手),其余的记不起来了。
二面:简历没怎么问了。C++(虚函数表),算法(两个矩形求交,顺子和同花计算概率),其余的也记不起来了。
三面:问了下就业意向,还有如何说明自己学习能力好。算法(大数组找中位数),其余的题目也记不起来了。
因为没抱什么希望,所以对offer也没什么感觉。因为不想去北京,后面hr叫过去谈offer的时候,差不多直接拒绝了,后面还是发了电子档的offer。
第五家,2014.10月,网易游戏,结果:终面挂了
参加笔试和面试一共跑了武汉两趟,也是悲剧。笔试是9月底,在华科。笔试很长的试卷,貌似是150分钟。前面是变态的基础题,后面是变态的算法题。笔试是通过了,
虽然做的乱七八糟了。最难看的是我的字迹。算法题:记得有个递归改非递归,四叉树,dp,还有k-d tree等等。。
面试一共是两面,一个上午面完的,面完之后感觉还不错,只是后面就没消息了。一面之前先手写了个代码题(我的是合并字符串,类似于归并排序的合并部分),
再拿过去给一面面试官,话说我硬是在那里等了一个小时,别人只需要等20分钟左右,真的很无解额。
一面:先也是针对简历,然后是c++,设计模式,算法,图形学之类的。C++(多态…),设计模式(貌似是个状态模式还是啥,我设计模式很渣),
算法(概率类dp,最优化搜索二叉树),图形学(glsl常识),更多的忘记了,过了一会儿就去二面了。
二面:二面面试官感觉人很和善,一直笑眯眯的。也问了很多问题,最后还聊了腾讯和网易这两家。开始也先是问简历,只是这次我说的不多,感觉不给力,说实话得注意突出自己。
C++(实现类的set和get),图形学(光照模型,glsl片元获得实际位置等),算法题(手写数组去重,线段树实现区间覆盖查询,我当时居然没说清楚线段树实现,败了),
感觉问题不多,聊得也不错。后面就问我拿到什么offer,我说了有腾讯的。然后,他就开始比较腾讯了,说了一些某些公司怎么样的话,进行了一些对比,也说了网易的培训机制。
这样一说,我就感觉我通过的可能性很大的。而且,最后他还送我出门,握手了,受宠若惊。只是最后居然没通知,非常意外的感觉。只能说,我还是太年轻了, 很多准备没做充分,好好努力吧。
PS:说实话,即使过了我也不一定去,因为我爸爸和叔叔在深圳那边上班。也感觉腾讯氛围和平台确实更舒服,虽然网易多几万的工资,也号称工资和奖金分开算。
不过,我既然去不了就永远不会知道内幕了。
这就是我找工作的整个过程,因为时间有点久了,记不起那么多了,再不写估计就忘记完了。感谢碰到的每个面试官,是你们让我成长和得到承认额,
尤其感觉腾讯的面试官,给了我人生的这次非常重要的机会。